


Lumiere - Google's AI Next level text to video (T2V)
Space-Time U-Net at works


In the realm of generative models for images, the progress has been staggering. Text-to-image (T2I) diffusion models now excel at synthesizing high-resolution, photorealistic images based on complex text prompts, enabling a multitude of image editing capabilities and downstream applications. However, when it comes to training large-scale text-to-video (T2V) foundation models, challenges arise due to the complexities introduced by motion.
The prevailing issue lies in achieving global temporal consistency, which is hindered by the traditional cascaded design adopted by existing T2V models. These models generate distant keyframes and subsequently use temporal super-resolution (TSR) modules to fill in the gaps between keyframes. While memory-efficient, this approach faces limitations in terms of generating globally coherent motion.
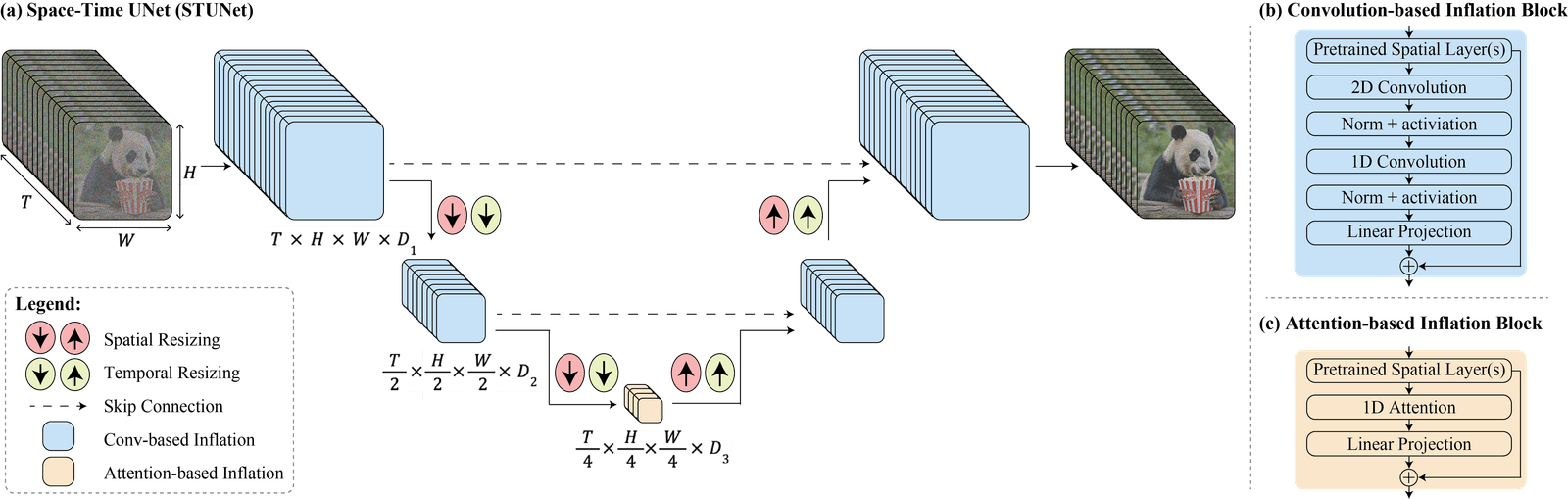
A new approach is introduced with Lumiere—a T2V diffusion framework that challenges the conventional cascaded design. Lumiere employs a Space-Time U-Net architecture, generating the entire temporal duration of a video in a single pass. This departure from the norm allows for more globally coherent motion, addressing the challenges posed by motion synthesis. Importantly, Lumiere's design includes both spatial and temporal down- and up-sampling, leveraging a pre-trained text-to-image model for enhanced results.
The innovative aspect of Lumiere lies in its ability to sidestep the use of a TSR cascade, making it more adaptable to downstream applications. This adaptability is showcased through video editing tasks and various content creation applications, such as image-to-video, inpainting, and stylized generation. Lumiere's capability to generate the full video at once proves advantageous, offering an intuitive interface for off-the-shelf editing and easing integration into a plethora of creative tasks.
The absence of a TSR cascade not only simplifies Lumiere's architecture but also extends its utility to downstream applications. This is demonstrated through video-to-video editing using SDEdit, showcasing Lumiere's potential for diverse applications. The subsequent discussion delves into specific applications, including style-conditioned generation, image-to-video synthesis, inpainting, outpainting, and cinemagraphs. Visual examples are presented, and further details are available in the Supplementary Material on Lumiere's webpage. Lumiere's unique design choices and benefits underscore its position at the forefront of text-to-video generation, promising a new frontier for creative content synthesis.
Style-conditioned generation
Drawing inspiration from successful Generative Adversarial Network (GAN)-based interpolation techniques (Pinkney & Adler, 2020), Lumiere introduced a nuanced strategy to balance style and motion. Linearly interpolating between the fine-tuned T2I weights (Wstyle) and the original T2I weights (Worig) via the formula Winterpolate = α·Wstyle + (1−α)·Worig, alse incorporated a manually chosen interpolation coefficient (α ∈ [0.5, 1]). This approach aims to generate videos that seamlessly incorporate the chosen style while maintaining plausible motion.
Image-to-video
The innovative approach involves presenting the first frame of a video as input to the model. The conditioning signal, encompasses this initial frame, succeeded by blank frames extending throughout the video. Simultaneously, a corresponding mask, assigns ones (representing unmasked content) to the first frame and zeros (indicating masked content) to the subsequent frames.

The standout feature of this groundbreaking technology is its ability to generate videos that not only commence with the desired first frame but also unfold with intricate and coherent motion throughout the entire video duration.
This remarkable advancement in video synthesis holds promise for diverse applications, from creative content creation to immersive storytelling, marking a significant stride forward in the realm of artificial intelligence and visual media.
Inpainting
The inpainting process achieves a seamless integration of new elements into the video, guided by the user's creative vision. Whether it's replacing objects or refining specific areas within the frame, this innovative technology promises a new era of video editing possibilities.

This transformative approach to video editing marks a significant leap forward in user-guided content manipulation within the dynamic realm of visual media.
Cinemagraphs
The conditioning signal is an input image replicated throughout the entire video. The mask plays a crucial role, featuring unmasked content for the entire first frame and subsequently masking the specified user-provided region in subsequent frames. The outcome? A mesmerizing video where the marked area comes to life in animated splendor, while the remainder remains gracefully static.
By keeping the first frame unmasked, our method ensures that the animated content seamlessly aligns with the visual attributes of the conditioning image. This revolutionary approach to image-based animation opens new doors for creative expression, promising to redefine the way we perceive and interact with visual content.
Social impact
At the core of our endeavor lies a commitment to empowering individuals, particularly novices, to unleash their creativity and forge compelling visual narratives. Yet, as with any powerful tool, there exists a potential for misuse, giving rise to concerns about the creation of deceptive or harmful content using our technology. Recognizing this responsibility, we prioritize the development and implementation of robust tools designed to detect biases and thwart malicious applications. Our unwavering dedication to fostering a safe and fair environment underscores the ethical considerations integral to the advancement of our cutting-edge technology. By proactively addressing these challenges, we aim to ensure that our innovation serves as a force for positive and responsible creativity in the visual content landscape.